

はじめに:文字コードって結局なに?
「UTF-8」「Unicode」「文字化け」「エンコード」――
応用情報を勉強しているとこれらの言葉をよく理解できていなかったなと実感しました
本記事では、「Unicode・UCS・UTFって何が違うの?」という疑問に、図と具体例を使って整理していきます
【図解】文字コード関連用語を整理
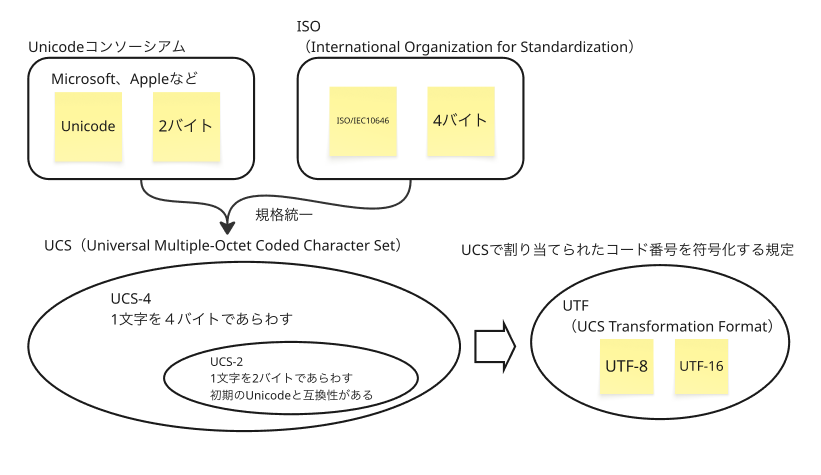
全体像をざっくり掴む
「文字セット」と「エンコーディング」は別物です
文字セット(Character Set)
- 「どんな文字があるか」と、それに割り当てられた番号(コードポイント)
- UCSやUnicodeなど
エンコーディング(Encoding)
- その番号をバイト列(010101…)に変換するルール
- UTF-8やUTF-16など
コードポイントとUTF-8の具体例は以下です
| 文字 | コードポイント | UTF-8(バイト列) |
|---|---|---|
| A | U+0041 | 41 |
| あ | U+3042 | E3 81 82 |
| 😀 | U+1F600 | F0 9F 98 80 |
UnicodeとUCSは「文字セット」
Unicodeとは
Unicodeは、世界中の文字に一意の番号(コードポイント)を割り当てる国際規格です。
例:「あ」は U+3042、 「漢」は U+6F22
UCSとは
- UCS(Universal Character Set)はISOの規格(ISO/IEC 10646)
- Unicodeを取り込んで制定された
- UCS-4やUCS-2がある
UTFとは「エンコーディング方式」
コードポイントをバイト列に変換する方法がUTF(UCS Transformation Format)です。
主なUTFの種類
| 方式 | 特徴 | 1文字のバイト数 |
|---|---|---|
| UTF-8 | 可変長、ASCII互換(最も普及) | 1〜4バイト |
| UTF-16 | 可変長 | 2 or 4バイト |
| UTF-32 | 固定長 | 常に4バイト |
例:文字「あ」の表現
| 方式 | バイト列(16進数) |
|---|---|
| UTF-8 | E3 81 82 |
| UTF-16 | 30 42 |
| UTF-32 | 00 00 30 42 |
UTF-8が普及しているのは、英数字が1バイトで済み、互換性が高いからです。
まとめ
| 項目 | 意味 |
|---|---|
| Unicode/UCS | 文字セット(どの文字にどんな番号か) |
| UTF-8など | エンコーディング(番号をどうバイトに) |
「文字コードってややこしい」と感じていた方も、この関係を押さえればスッキリ理解できます。
試験対策だけでなく、実務の場でも役立つ知識なので、ぜひこの機会にマスターしておきましょう!


コメント